At times, companies do change their names and due which in the stock exchanges their ticker changes. In NSE, this ticker is called as “SYMBOL” atleast they used to be.
These changes are available in NSE Website here
These change in symbol csv file link is
CSV file looks like this,
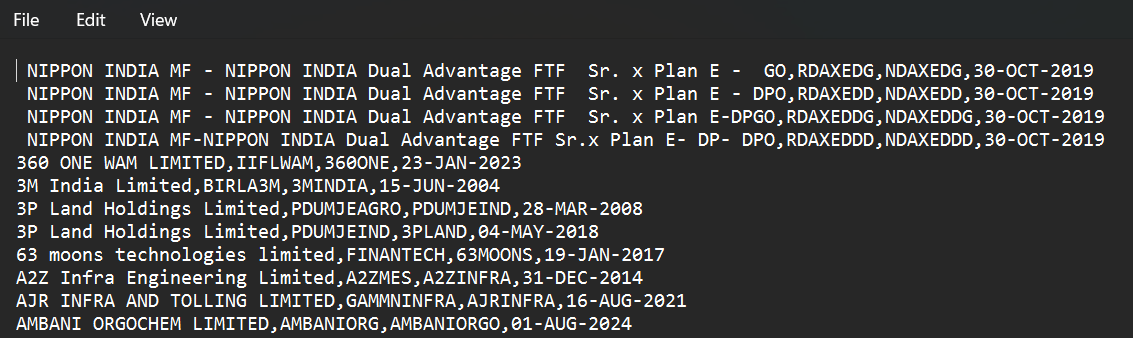
So, when you are doing an analysis with Bhavcopy data, if a company changes their symbol, you got to handle it somehow. So, the method, i am using below is, i’m updating the past symbol to the latest/current symbol.
Lets say, you downloaded that file and read that file into a dataframe like below,
# Read the CSV content into a Pandas DataFrame
df_symchange = pd.read_csv(csv_data, names=colnames, header=None)
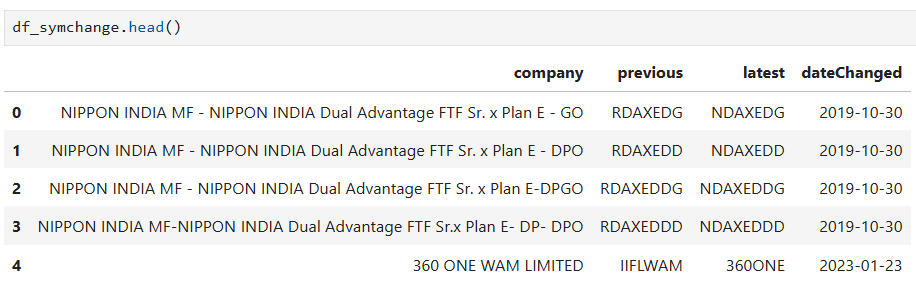
Below is what i had tried,
time
df_nse = df_nse5y.copy()
# Convert date columns to datetime
df_symchange["dateChanged"] = pd.to_datetime(df_symchange["dateChanged"])
df_nse["Date"] = pd.to_datetime(df_nse["Date"])
# Sort df_symchange by dateChanged to process changes in chronological order
df_symchange = df_symchange.sort_values(by='dateChanged', ascending=True).reset_index(drop=True)
# Map changes using a cumulative replacement strategy
df_nse = df_nse.merge(
df_symchange,
left_on="Stock",
right_on="previous",
how="left",
suffixes=("", "_change")
)
# Replace the stock symbol where the date is within the change window
df_nse["Stock"] = df_nse.apply(
lambda row: row["latest"] if pd.notnull(row["dateChanged"]) and row["Date"] <= row["dateChanged"] else row["Stock"],
axis=1
)
# Drop extra columns added during the merge
df_nse.drop(columns=["previous", "latest", "dateChanged", "company"], inplace=True)
This took,
CPU times: total: 4.53 s
Wall time: 4.6 s
Vectorization usually doesn’t work for me, like outputs wouldn’t match up. This matched.
This is the code, i use to compare dataframes,
def compare_dataframes(df1, df2):
# Fill missing values with a placeholder before comparison
df1_filled = df1.fillna('missing')
df2_filled = df2.fillna('missing')
# Compare element-wise
comparison = df1_filled == df2_filled
# Check where values differ
differences = ~comparison
# Find mismatched rows and columns
mismatched = differences.any(axis=1) # Rows with differences
print("Number of mismatched rows:", mismatched.sum())
print("Rows with differences:\n", df1[mismatched].shape)
Inputs
compare_dataframes(df_nse1, df_nse3)
Output
Number of mismatched rows: 0
Rows with differences:
(0, 5)
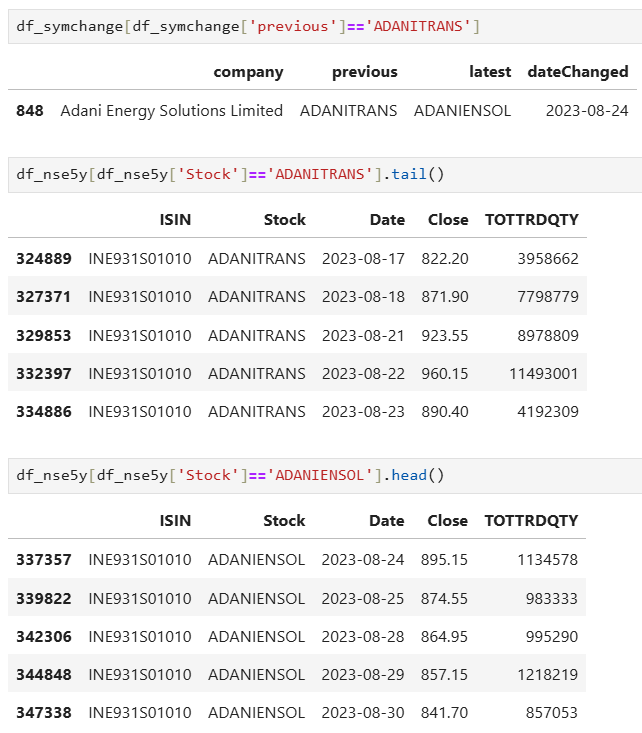
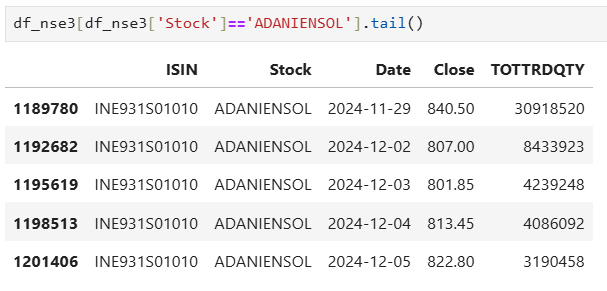
After running the program, ‘ADANITRANS’ is updated as ‘ADANIENSOL’
That’s all for now