When you start to program big or start to process bigger data than usual, you can notice slowness sometimes. It could be due to memory used in the laptop at that time. You can retry after shutting down all the application which you have been running parallely. If its still slow, it must because of your code. Easiest way to spot slow section of the code is by setting up timers,
from time import time, sleep
step_start = time()
### Some big process start
sleep(2.4)
### Some big process end
step_et = time()-step_start
print("=== {} Total Elapsed time is {} sec\n".format('Sleeping', round(step_et,3) )) If you want to know how much time entire program takes, you can do something like this,
$ time python BTD-Analysis1V3.py
getcwd : D:\BigData\12. Python\5. BTD\progs
Length of weekly = 53
real 0m5.441s
user 0m0.000s
sys 0m0.062sIts not always a good strategy to guess or follow the gut-feeling in identifying performance problems, things can surprise you.
If you are looking for more information than the above timers like number of calls, execution time then you should look into Python profilers.
What’s Python Profiling ? As per the doc
A profile is a set of statistics that describes how often and for how long various parts of the program executed.
Here we are going to see two profilers,
- cProfile
- line_profile
# cProfile
This profiler comes in the standard python installation. Easiest way to profile a program is like below,
python -m cProfile -s cumtime BTD-Analysis1V3.py
# output
Sushanth@Sushanth-VAIO MINGW64 /d/BigData/12. Python/5. BTD/progs
$ python -m cProfile -s cumtime BTD-Analysis1V3.py
getcwd : D:\BigData\12. Python\5. BTD\progs
Length of weekly = 53
323489 function calls (315860 primitive calls) in 5.602 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
751/1 0.029 0.000 5.606 5.606 {built-in method builtins.exec}
1 0.000 0.000 5.606 5.606 BTD-Analysis1V3.py:2(<module>)
2 0.000 0.000 3.911 1.955 parsers.py:536(parser_f)
2 0.036 0.018 3.911 1.955 parsers.py:403(_read)
2 0.002 0.001 3.804 1.902 parsers.py:1137(read)
...This could give you huge information, if your program is big.
| Fields | Description |
|---|---|
| ncalls | How many times code was called |
| tottime | Total time it took(excluding the time of other functions) |
| percall | How long each call took |
| cumtime | Total time it took(including the time of other functions) |
You can redirect the output to a text file or dump the stats using the -o output filename option in command.
python -m cProfile -o profile_output BTD-Analysis1V3.pyBy using the output file option, you get additional information like,
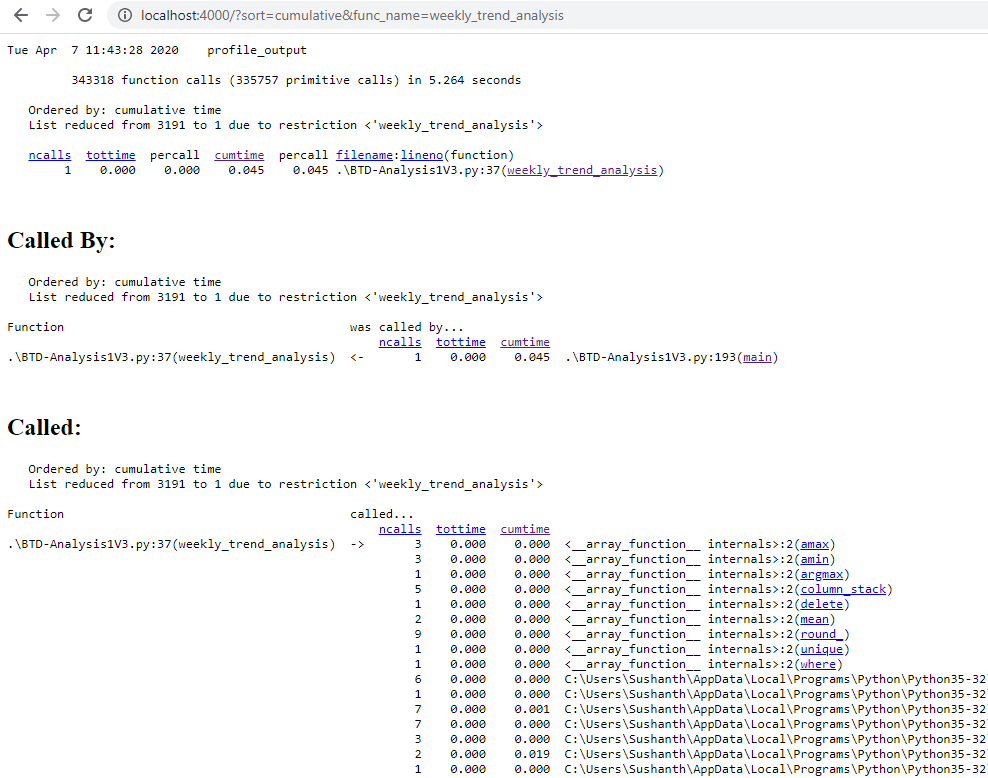
- Callers - What function it called
- Callees - What function called it
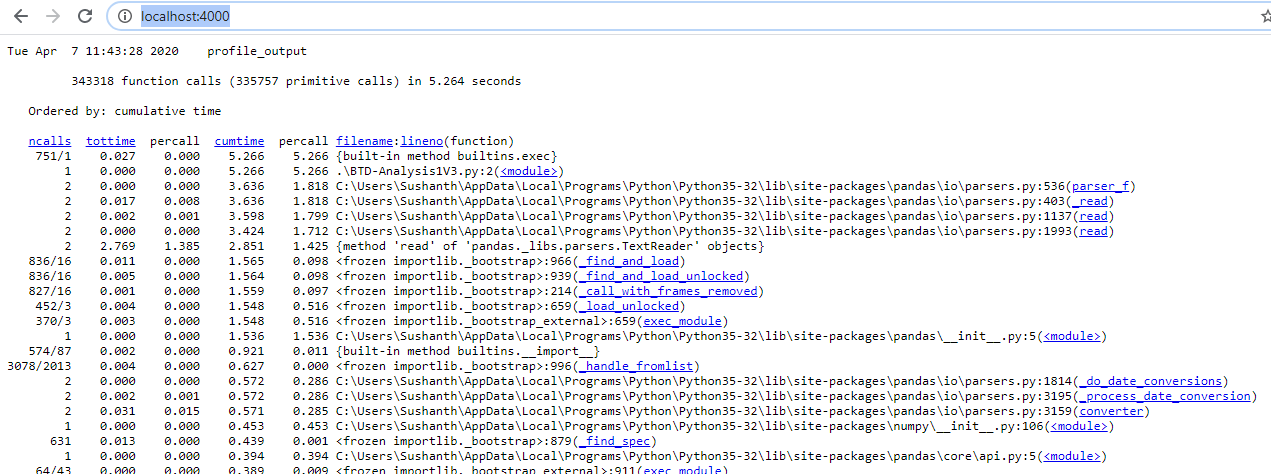
Catch is, this output file is binary. To read this binary file you need to use pstats. All these things sound pretty much tedious. Luckily i found a package called cprofilev which reads this output file and starts a server and in the localhost, where you can see all the profiling information.
Author of the tool : ymichael
Below are the steps,
# Install
sudo pip install cprofilev
# Specify the profile output filename
cprofilev -f profile_outputNow go and check http://localhost:4000/. You will see the stats, you can sort on the fields and click on function name links.
# line_profiler
Problem with this is, i couldn’t install line-profiler in Windows 10, failed due to below error and first thing that came to my mind is “i should give up line profiling as it is not getting installed” next thought is “Will this work in Cloud shell”.
Building wheels for collected packages: line-profiler
Building wheel for line-profiler (PEP 517) ... error
ERROR: Command errored out with exit status 1:
command: 'c:\users\sushanth\appdata\local\programs\python\python35-32\python.exe' 'c:\users\sushanth\appdata\local\programs\python\python35-32\lib\site-packages\pip\_vendor\pep517\_in_process.py' build_wheel 'C:\Users\Sushanth\AppData\Local\Temp\tmpktd1yk7q'
cwd: C:\Users\Sushanth\AppData\Local\Temp\pip-install-4bud8_nu\line-profiler
Complete output (322 lines):
Not searching for unused variables given on the command line.
-- The C compiler identification is unknown
CMake Error at CMakeLists.txt:3 (ENABLE_LANGUAGE):
No CMAKE_C_COMPILER could be found.
Tell CMake where to find the compiler by setting either the environment
variable "CC" or the CMake cache entry CMAKE_C_COMPILER to the full path to
the compiler, or to the compiler name if it is in the PATH.
-- Configuring incomplete, errors occurred!
See also "C:/Users/Sushanth/AppData/Local/Temp/pip-install-4bud8_nu/line-profiler/_cmake_test_compile/build/CMakeFiles/CMakeOutput.log".
See also "C:/Users/Sushanth/AppData/Local/Temp/pip-install-4bud8_nu/line-profiler/_cmake_test_compile/build/CMakeFiles/CMakeError.log".
Not searching for unused variables given on the command line.
CMake Error at CMakeLists.txt:2 (PROJECT):
Generator
Visual Studio 15 2017
could not find any instance of Visual Studio.
...
ERROR: Failed building wheel for line-profiler
Failed to build line-profiler
ERROR: Could not build wheels for line-profiler which use PEP 517 and cannot be installed directly
I use Windows 10 machine and to solve the above issue, i took the below steps.
-
Logged into my google console
-
Went to Cloud Storage and created a new bucket
-
Drag and drop files to the bucket ( data files, python file )
-
Open Cloud Shell and i ran the below commands to set the environment,
gcloud config set project <<project-id>>You can get the project-id by clicking on the top droplist, a small window will open to select the project, where you can see the project-id.
-
Installed all the required libraries, since its only few
pip install numpy_indexed pip install pandas pip install line-profiler -
Tested with a small program to see if line profiler works
test-lp.pyfrom line_profiler import LineProfiler import random def do_stuff(numbers): s = sum(numbers) l = [numbers[i]/43 for i in range(len(numbers))] m = ['hello'+str(numbers[i]) for i in range(len(numbers))] numbers = [random.randint(1,100) for i in range(1000)] lp = LineProfiler() lp_wrapper = lp(do_stuff) lp_wrapper(numbers) lp.print_stats() -
Made changes to the source code for line_profiler. Added import for line_profiler,
from line_profiler import LineProfilerIn my original, i call the function like this,
df_weekly2 = weekly_trend_analysis(exchange, df_weekly, df_daily)To profile, i modified the code like this
lp = LineProfiler() lp_wrapper = lp(weekly_trend_analysis) lp_wrapper(exchange, df_weekly, df_daily) lp.print_stats() -
Generates a big output, so its better to save it
python BTD-Analysis1V3.py > BTD-Prof.txt -
When everything is done here, copying outputs & files to cloud storage.
gsutil -m cp -r BTD-Analysis1V3.py gs://test-20200407/BTD_Analysis1V3-lp.py gsutil -m cp -r BTD-Prof.txt gs://test-20200407/BTD-Prof.txt -
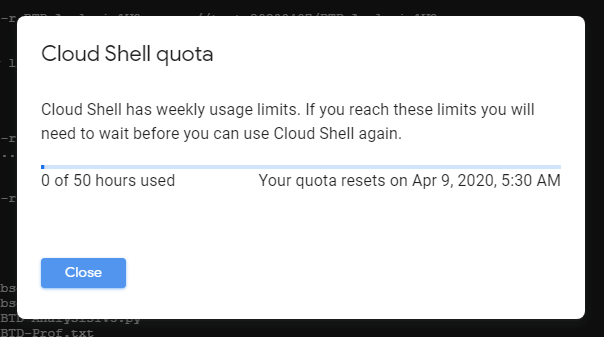
Cloud shell also has a Quota, watch out for it.
And you are done.
I find Cloud shell handy in doing things like this.
This is how the line-profiler output looks like and i started to work on the code with big Time values.
Details are in here
('getcwd : ', '/home/bobby_dreamer')
Timer unit: 1e-06 s
Total time: 0.043637 s
File: BTD-Analysis1V3.py
Function: weekly_trend_analysis at line 36
Line # Hits Time Per Hit % Time Line Contents
==============================================================
36 def weekly_trend_analysis(exchange, df_weekly_all, df_daily):
37
38 1 3.0 3.0 0.0 if exchange == 'BSE':
39 1 963.0 963.0 2.2 ticker = df_daily.iloc[0]['sc_code']
40 else:
41 ticker = df_daily.iloc[0]['symbol']
42
43 1 201.0 201.0 0.5 arr_yearWeek = df_daily['yearWeek'].to_numpy()
44 1 100.0 100.0 0.2 arr_close = df_daily['close'].to_numpy()
45 1 87.0 87.0 0.2 arr_prevclose = df_daily['prevclose'].to_numpy()
46 1 85.0 85.0 0.2 arr_chng = df_daily['chng'].to_numpy()
47 1 83.0 83.0 0.2 arr_chngp = df_daily['chngp'].to_numpy()
48 1 108.0 108.0 0.2 arr_ts = df_daily['ts'].to_numpy()
49 1 89.0 89.0 0.2 arr_volumes = df_daily['volumes'].to_numpy()
50
51 # Close
52 1 41.0 41.0 0.1 arr_concat = np.column_stack((arr_yearWeek, arr_close))
53 1 241.0 241.0 0.6 npi_gb = npi.group_by(arr_concat[:, 0]).split(arr_concat[:, 1])
54
55 #a = df_temp[['yearWeek', 'close']].to_numpy()
56 1 113.0 113.0 0.3 yearWeek, daysTraded = np.unique(arr_concat[:,0], return_counts=True)
57
58 1 4.0 4.0 0.0 cmaxs, cmins = [], []
59 1 3.0 3.0 0.0 first, last, wChng, wChngp = [], [], [], []
60 2 11.0 5.5 0.0 for idx,subarr in enumerate(npi_gb):
61 1 32.0 32.0 0.1 cmaxs.append( np.amax(subarr) )
62 1 17.0 17.0 0.0 cmins.append( np.amin(subarr) )
63 1 2.0 2.0 0.0 first.append(subarr[0])
64 1 2.0 2.0 0.0 last.append(subarr[-1])
65 1 3.0 3.0 0.0 wChng.append( subarr[-1] - subarr[0] )
66 1 6.0 6.0 0.0 wChngp.append( ( (subarr[-1] / subarr[0]) * 100) - 100 )
67
68 #npi_gb.clear()
69 1 4.0 4.0 0.0 arr_concat = np.empty((100,100))
70
71 # Chng
72 1 21.0 21.0 0.0 arr_concat = np.column_stack((arr_yearWeek, arr_chng))
73 1 109.0 109.0 0.2 npi_gb = npi.group_by(arr_concat[:, 0]).split(arr_concat[:, 1])
74
75 1 2.0 2.0 0.0 HSDL, HSDG = [], []
76 2 7.0 3.5 0.0 for idx,subarr in enumerate(npi_gb):
77 1 12.0 12.0 0.0 HSDL.append( np.amin(subarr) )
78 1 9.0 9.0 0.0 HSDG.append( np.amax(subarr) )
79
80 #npi_gb.clear()
81 1 3.0 3.0 0.0 arr_concat = np.empty((100,100))
82
83 # Chngp
84 1 15.0 15.0 0.0 arr_concat = np.column_stack((arr_yearWeek, arr_chngp))
85 1 86.0 86.0 0.2 npi_gb = npi.group_by(arr_concat[:, 0]).split(arr_concat[:, 1])
86
87 1 1.0 1.0 0.0 HSDLp, HSDGp = [], []
88 2 7.0 3.5 0.0 for idx,subarr in enumerate(npi_gb):
89 1 11.0 11.0 0.0 HSDLp.append( np.amin(subarr) )
90 1 9.0 9.0 0.0 HSDGp.append( np.amax(subarr) )
91
92 #npi_gb.clear()
93 1 3.0 3.0 0.0 arr_concat = np.empty((100,100))
94
95 # Last Traded Date of the Week
96 1 3111.0 3111.0 7.1 i = df_daily[['yearWeek', 'ts']].to_numpy()
97 1 128.0 128.0 0.3 j = npi.group_by(i[:, 0]).split(i[:, 1])
98
99 1 2.0 2.0 0.0 lastTrdDoW = []
100 2 9.0 4.5 0.0 for idx,subarr in enumerate(j):
101 1 2.0 2.0 0.0 lastTrdDoW.append( subarr[-1] )
102
103 1 4.0 4.0 0.0 i = np.empty((100,100))
104 #j.clear()
105
106 # Times inreased
107 1 11.0 11.0 0.0 TI = np.where(arr_close > arr_prevclose, 1, 0)
108
109 # Below npi_gb_yearWeekTI is used in volumes section
110 1 19.0 19.0 0.0 arr_concat = np.column_stack((arr_yearWeek, TI))
111 1 111.0 111.0 0.3 npi_gb_yearWeekTI = npi.group_by(arr_concat[:, 0]).split(arr_concat[:, 1])
112
113 1 73.0 73.0 0.2 tempArr, TI = npi.group_by(arr_yearWeek).sum(TI)
114
115 # Volume ( dependent on above section value t_group , thats the reason to move from top to here)
116 1 39.0 39.0 0.1 arr_concat = np.column_stack((arr_yearWeek, arr_volumes))
117 1 94.0 94.0 0.2 npi_gb = npi.group_by(arr_concat[:, 0]).split(arr_concat[:, 1])
118
119 1 2.0 2.0 0.0 vmaxs, vavgs, volAvgWOhv, HVdAV, CPveoHVD, lastDVotWk, lastDVdAV = [], [], [], [], [], [], []
120 2 8.0 4.0 0.0 for idx,subarr in enumerate(npi_gb):
121 1 53.0 53.0 0.1 vavgs.append( np.mean(subarr) )
122 1 2.0 2.0 0.0 ldvotWk = subarr[-1]
123 1 2.0 2.0 0.0 lastDVotWk.append(ldvotWk)
124
125 #print(idx, 'O - ',subarr, np.argmax(subarr), ', average : ',np.mean(subarr))
126 1 13.0 13.0 0.0 ixDel = np.argmax(subarr)
127 1 2.0 2.0 0.0 hV = subarr[ixDel]
128 1 2.0 2.0 0.0 vmaxs.append( hV )
129
130 1 1.0 1.0 0.0 if(len(subarr)>1):
131 1 53.0 53.0 0.1 subarr = np.delete(subarr, ixDel)
132 1 29.0 29.0 0.1 vawoHV = np.mean(subarr)
133 else:
134 vawoHV = np.mean(subarr)
135 1 2.0 2.0 0.0 volAvgWOhv.append( vawoHV )
136 1 12.0 12.0 0.0 HVdAV.append(hV / vawoHV)
137 1 3.0 3.0 0.0 CPveoHVD.append( npi_gb_yearWeekTI[idx][ixDel] )
138 1 6.0 6.0 0.0 lastDVdAV.append(ldvotWk / vawoHV)
139
140 #npi_gb.clear()
141 1 3.0 3.0 0.0 arr_concat = np.empty((100,100))
142
143 # Preparing the dataframe
144 # yearWeek and occurances
145 #yearWeek, daysTraded = np.unique(a[:,0], return_counts=True)
146 1 5.0 5.0 0.0 yearWeek = yearWeek.astype(int)
147 1 44.0 44.0 0.1 HSDL = np.round(HSDL,2)
148 1 21.0 21.0 0.0 HSDG = np.round(HSDG,2)
149 1 18.0 18.0 0.0 HSDLp = np.round(HSDLp,2)
150 1 18.0 18.0 0.0 HSDGp = np.round(HSDGp,2)
151
152 1 17.0 17.0 0.0 first = np.round(first,2)
153 1 17.0 17.0 0.0 last = np.round(last,2)
154 1 17.0 17.0 0.0 wChng = np.round(wChng,2)
155 1 16.0 16.0 0.0 wChngp = np.round(wChngp,2)
156
157 1 5.0 5.0 0.0 vavgs = np.array(vavgs).astype(int)
158 1 3.0 3.0 0.0 volAvgWOhv = np.array(volAvgWOhv).astype(int)
159 1 17.0 17.0 0.0 HVdAV = np.round(HVdAV,2)
160
161 1 3.0 3.0 0.0 dict_temp = {'yearWeek': yearWeek, 'closeH': cmaxs, 'closeL': cmins, 'volHigh':vmaxs, 'volAvg':vavgs, 'daysTraded':daysTraded
162 1 2.0 2.0 0.0 ,'HSDL':HSDL, 'HSDG':HSDG, 'HSDLp':HSDLp, 'HSDGp':HSDGp, 'first':first, 'last':last, 'wChng':wChng, 'wChngp':wChngp
163 1 2.0 2.0 0.0 ,'lastTrdDoW':lastTrdDoW, 'TI':TI, 'volAvgWOhv':volAvgWOhv, 'HVdAV':HVdAV, 'CPveoHVD':CPveoHVD
164 1 2.0 2.0 0.0 ,'lastDVotWk':lastDVotWk, 'lastDVdAV':lastDVdAV}
165 1 3677.0 3677.0 8.4 df_weekly = pd.DataFrame(data=dict_temp)
166
167 1 1102.0 1102.0 2.5 df_weekly['sc_code'] = ticker
168
169 1 3.0 3.0 0.0 cols = ['sc_code', 'yearWeek', 'lastTrdDoW', 'daysTraded', 'closeL', 'closeH', 'volAvg', 'volHigh'
170 1 1.0 1.0 0.0 , 'HSDL', 'HSDG', 'HSDLp', 'HSDGp', 'first', 'last', 'wChng', 'wChngp', 'TI', 'volAvgWOhv', 'HVdAV'
171 1 2.0 2.0 0.0 , 'CPveoHVD', 'lastDVotWk', 'lastDVdAV']
172
173 1 2816.0 2816.0 6.5 df_weekly = df_weekly[cols].copy()
174
175 # df_weekly_all will be 0, when its a new company or its a FTA(First Time Analysis)
176 1 13.0 13.0 0.0 if df_weekly_all.shape[0] == 0:
177 1 20473.0 20473.0 46.9 df_weekly_all = pd.DataFrame(columns=list(df_weekly.columns))
178
179 # Removing all yearWeek in df_weekly2 from df_weekly
180 1 321.0 321.0 0.7 a = set(df_weekly_all['yearWeek'])
181 1 190.0 190.0 0.4 b = set(df_weekly['yearWeek'])
182 1 5.0 5.0 0.0 c = list(a.difference(b))
183 #print('df_weekly_all={}, df_weekly={}, difference={}'.format(len(a), len(b), len(c)) )
184 1 1538.0 1538.0 3.5 df_weekly_all = df_weekly_all[df_weekly_all.yearWeek.isin(c)].copy()
185
186 # Append the latest week data to df_weekly
187 1 6998.0 6998.0 16.0 df_weekly_all = pd.concat([df_weekly_all, df_weekly], sort=False)
188 #print('After concat : df_weekly_all={}'.format(df_weekly_all.shape[0]))
189
190 1 2.0 2.0 0.0 return df_weekly_all
# Resources
- StackOverflow - How do I use line_profiler (from Robert Kern)?
- line-profiler-code-example
- line-profiler without magic
- Github - line_profiler