Below picture shows options available to load BigQuery
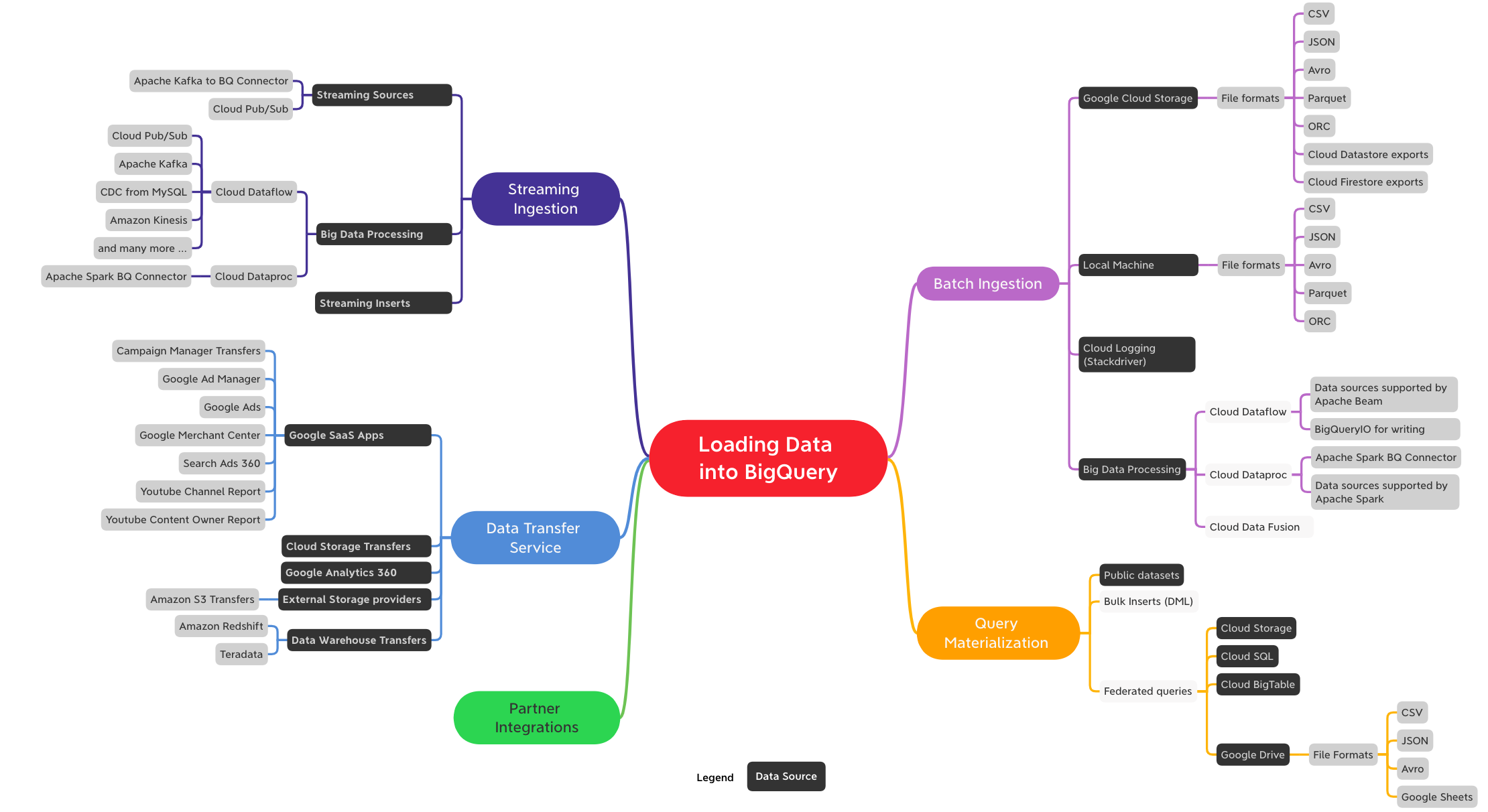
Below are some sample programs and options which i am using currently or plan to use,
Loading from Local
This program is used to load data in a CSV file extracted from mySQL table into BigQuery. The program does following activities,
- Pre-process(strips spaces) data and saves it in a new file with prefix ‘pp-’
- Load data from local into BigQuery
Some Pre-reqs
import csv
from datetime import datetime
from google.cloud import bigquery
def load_bq(pp_file, table_id, load_type):
with open(pp_file) as f:
all_cols_from_file = f.readline()
all_cols_from_file=all_cols_from_file.rstrip('\n').upper().split(',')
print(all_cols_from_file)
# Construct a BigQuery client object.
client = bigquery.Client()
# Post-2014
schema = [{'name': 'ts', 'type': 'DATE', 'mode': 'REQUIRED'}, {'name': 'sc_code', 'type': 'INTEGER', 'mode': 'REQUIRED'}, {'name': 'sc_name', 'type': 'STRING', 'mode': 'REQUIRED'}, {'name': 'sc_group', 'type': 'STRING', 'mode': 'REQUIRED'}, {'name': 'sc_type', 'type': 'STRING', 'mode': 'REQUIRED'}, {'name': 'open', 'type': 'NUMERIC', 'mode': 'REQUIRED'}, {'name': 'high', 'type': 'NUMERIC', 'mode': 'REQUIRED'}, {'name': 'low', 'type': 'NUMERIC', 'mode': 'REQUIRED'}, {'name': 'close', 'type': 'NUMERIC', 'mode': 'REQUIRED'}, {'name': 'last', 'type': 'NUMERIC', 'mode': 'REQUIRED'}, {'name': 'prevclose', 'type': 'NUMERIC', 'mode': 'REQUIRED'}, {'name': 'no_trades', 'type': 'INTEGER', 'mode': 'REQUIRED'}, {'name': 'NO_OF_SHRS', 'type': 'INTEGER', 'mode': 'REQUIRED'}, {'name': 'NET_TURNOVER', 'type': 'NUMERIC', 'mode': 'REQUIRED'}, {'name': 'TDCLOINDI', 'type': 'STRING', 'mode': 'NULLABLE'}, {'name': 'ISIN', 'type': 'STRING', 'mode': 'NULLABLE'}]
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.CSV, skip_leading_rows=1,
schema=schema,
write_disposition=load_type,
null_marker='\\N' # mySQL marks null value by \N
)
# Loading CSV file from local system
with open(pp_file, "rb") as source_file:
job = client.load_table_from_file(source_file, table_id, job_config=job_config)
# Loading CSV file from GCS
# uri = "gs://<<bucket-name>>/bse/bhavcopy_csv/EQ_ISINCODE_280921.CSV"
# job = client.load_table_from_uri(uri, table_id, job_config=job_config)
job.result() # Waits for the job to complete.
print(job)
table = client.get_table(table_id) # Make an API request.
print(
"Loaded {} rows and {} columns to {}".format(
table.num_rows, len(table.schema), table_id
)
)
def preprocess_file(input_filename):
# ---- PreProcess CSV save as new file ----
temp_folder = '/tmp/'
ppCSV = temp_folder+'pp-'+input_filename
with open(input_filename, 'r') as inf, open(ppCSV, 'w', newline='') as of:
r = csv.reader(inf, delimiter=',')
w = csv.writer(of, delimiter=',')
total_rows = 0
for line in r:
total_rows+=1
trim = (field.strip() for field in line)
# trim = (field.replace('\\N', '') for field in line)
w.writerow(trim)
return ppCSV
def main():
input_filename = 'test-bse-data.csv'
# `<<project-name>>.btd_in3.bse_daily_history`
table_name = 'bse_daily_history'
table_id = '{}.{}.{}'.format('<<project-name>>', 'btd_in3', table_name)
pp_file = preprocess_file(input_filename)
load_bq(pp_file, table_id, 'WRITE_APPEND')
if __name__ == "__main__":
main()Input file looks like this
ts,sc_code,sc_name,sc_group,sc_type,open,high,low,close,last,prevclose,no_trades,NO_OF_SHRS,NET_TURNOVER,TDCLOINDI,ISIN
2020-09-08,542963,06AGG,F,Q,0.94,0.94,0.94,0.94,0.94,0.86,1,50,47,\N,INF204KB12L0
2020-09-08,936963,0ECL21,F,D,1000.00,1000.00,1000.00,1000.00,1000.00,1000.00,1,10,10000,\N,INE804IA7188
2020-09-08,937079,0EFIL21,F,D,995.00,995.00,995.00,995.00,995.00,992.25,3,25,24875,\N,INE918K07FO1
2020-09-08,936710,0EFL21A,F,D,1050.10,1099.90,1050.10,1099.90,1099.90,1099.90,2,11,11600,\N,INE804IA7071
2020-09-08,936720,0EFL24,F,D,940.00,940.00,920.00,920.00,920.00,945.00,29,2055,1891480,\N,INE804IA7121
2020-09-08,935790,0EHFL26,F,D,738.00,738.00,738.00,738.00,738.00,918.80,1,1,738,\N,INE530L07236
2020-09-08,936508,0ICFL24,F,D,925.10,925.10,800.05,900.00,900.00,999.95,5,135,123960,\N,INE614X07092Command used to unload data from mySQL is below, first select is header and second is the SQL to select data.
select * from (
select 'ts', 'sc_code', 'sc_name', 'sc_group', 'sc_type', 'open', 'high', 'low', 'close', 'last', 'prevclose', 'no_trades', 'NO_OF_SHRS', 'NET_TURNOVER', 'TDCLOINDI', 'ISIN'
union all
select date(ts) ts, sc_code, sc_name, sc_group, sc_type, open, high, low, close, last, prevclose, no_trades, NO_OF_SHRS, NET_TURNOVER, TDCLOINDI, ISIN from bse_daily_history)a
INTO OUTFILE 'D:/BigData/12. Python/1. Tryouts/GCP/OTLs-BQ/bse-2014-2020.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\r\n' ;Another interesting thing in the above program is the specification of BigQuery Schema. Below query is used to extract the mySQL column information.
SELECT COLUMN_NAME,
CASE
WHEN data_type = 'datetime' then "DATE"
WHEN data_type = 'bigint' then "INTEGER"
WHEN data_type = 'varchar' then "STRING"
WHEN data_type = 'decimal' then "NUMERIC"
WHEN data_type = 'char' then "STRING"
END as BQ_DATA_TYPE,
CASE
WHEN IS_NULLABLE = 'NO' then "REQUIRED"
WHEN IS_NULLABLE = 'YES' then "NULLABLE"
END as BQ_MODE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE table_name = 'bse_daily_history'
AND table_schema = 'test'
INTO OUTFILE 'D:/BigData/12. Python/1. Tryouts/GCP/OTLs-BQ/schema-bse_daily_history.txt' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\r\n' ;Output to the above SQL looks like this
ts,DATE,REQUIRED
sc_code,INTEGER,REQUIRED
sc_name,STRING,REQUIRED
sc_group,STRING,REQUIRED
sc_type,STRING,REQUIRED
open,NUMERIC,REQUIRED
high,NUMERIC,REQUIRED
low,NUMERIC,REQUIRED
close,NUMERIC,REQUIRED
last,NUMERIC,REQUIRED
prevclose,NUMERIC,REQUIRED
no_trades,INTEGER,REQUIRED
NO_OF_SHRS,INTEGER,REQUIRED
NET_TURNOVER,INTEGER,REQUIRED
TDCLOINDI,STRING,NULLABLE
ISIN,STRING,NULLABLEAbove file is read by the below python program to generate array of dictionary objects.
# BigQuery Schema Generator
import csv
arr = []
with open("schema-bse_daily_history.txt", "r") as f:
reader = csv.reader(f, delimiter=",")
for i, line in enumerate(reader):
dict = {}
print('line[{}] = {}'.format(i, line))
dict['name'] = line[0]
dict['type'] = line[1]
dict['mode'] = line[2]
arr.append(dict)
print(arr)Loading from GCS
Loading BigQuery from GCS isn’t much different when comparing loading from local file. In the earlier program uncommenting below lines enables it load data from GCS. Thats pretty much it.
# Loading CSV file from GCS
uri = "gs://<<bucket-name>>/bse/bhavcopy_csv/EQ_ISINCODE_280921.CSV"
job = client.load_table_from_uri(uri, table_id, job_config=job_config) Loading a Dataframe
This program uses an external library pandas_gbq to load BigQuery
Program does the following,
- Extracts date from filename
- Reads the CSV file to get all the header columns
- Pandas dataframe uses only only few specific column mentioned in variable
bse_csv_columns - Adds a new date object column to dataframe
- Finally data is loaded into BQ
# Default Installs
import os
import pandas as pd
from datetime import datetime
import pandas_gbq
# Functions
# Formatting Date
get_datetime = lambda s: datetime.strptime(s, '%d%m%y').date()
def csv_to_df(filename):
"""
Read BSE Daily csv file and return dataframe
:param filename: CSV Filename
"""
date = get_datetime(filename[-10:-4])
print(date)
with open(filename) as f:
all_cols_from_file = f.readline()
all_cols_from_file=all_cols_from_file.upper().split(',')
# print(all_cols_from_file)
# Columns
# SC_CODE,SC_NAME,SC_GROUP,SC_TYPE,OPEN,HIGH,LOW,CLOSE,LAST,PREVCLOSE,NO_TRADES,NO_OF_SHRS,NET_TURNOV,TDCLOINDI,ISIN_CODE,TRADING_DATE,FILLER2,FILLER3
bse_csv_columns = ["SC_CODE","SC_NAME","SC_GROUP","SC_TYPE"
,"OPEN","HIGH","LOW","CLOSE","LAST","PREVCLOSE"
,"NO_TRADES","NO_OF_SHRS","NET_TURNOV","TDCLOINDI","ISIN_CODE"]
df_bse_daily = pd.read_csv(os.path.join(os.getcwd(), filename), sep=','
, names=all_cols_from_file
, usecols=bse_csv_columns
,skiprows=1
,dtype=object
,skip_blank_lines=True)
# df_bse_daily['TS'] = date
print(df_bse_daily.info())
return df_bse_daily
def load_bigquery(df):
pandas_gbq.to_gbq(
df, 'BTD_20210925.bse_daily_str', project_id='<<project-name>>', if_exists='replace')
def main():
print('getcwd : ', os.getcwd())
df = csv_to_df('EQ_ISINCODE_010119.CSV')
# print(df.columns)
# print(df.head())
load_bigquery(df)
if __name__ == "__main__":
main()Input file looks like this
SC_CODE,SC_NAME,SC_GROUP,SC_TYPE,OPEN,HIGH,LOW,CLOSE,LAST,PREVCLOSE,NO_TRADES,NO_OF_SHRS,NET_TURNOV,TDCLOINDI,ISIN_CODE,TRADING_DATE,FILLER2,FILLER3
500002,ABB LTD. ,A ,Q,1318.20,1338.75,1312.55,1320.40,1323.55,1332.00,255,1816,2407362.00,,INE117A01022,01-Jan-19,,
500003,AEGIS LOGIS ,A ,Q,204.75,205.70,200.60,203.90,203.90,204.20,294,5672,1150504.00,,INE208C01025,01-Jan-19,,
500008,AMAR RAJA BA,A ,Q,743.45,747.50,737.60,739.65,739.65,742.75,253,7307,5424260.00,,INE885A01032,01-Jan-19,,
500009,A.SARABHAI ,X ,Q,13.60,13.75,13.00,13.43,13.44,13.24,41,12887,172463.00,,INE432A01017,01-Jan-19,,
500010,HDFC ,A ,Q,1973.55,2018.60,1956.00,2009.60,2009.60,1970.00,2531,320697,630395875.00,,INE001A01036,01-Jan-19,,Loading a JSON
Loading newline delimited JSON file from Cloud Storage
This is pretty much straight forward, its a from google samples to load json data from Cloud Storage
# Load JSON from Cloud Storage to BQ
import io
from google.cloud import bigquery
# Construct a BigQuery client object.
client = bigquery.Client()
# TODO(developer): Set table_id to the ID of the table to create.
table_id = "<<project-name>>.test_public_data.us_states_jl"
job_config = bigquery.LoadJobConfig(
write_disposition=bigquery.WriteDisposition.WRITE_TRUNCATE,
source_format=bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
schema=[
bigquery.SchemaField("name", "STRING"),
bigquery.SchemaField("post_abbr", "STRING"),
],
)
uri = "gs://cloud-samples-data/bigquery/us-states/us-states.json"
load_job = client.load_table_from_uri(
uri, table_id, job_config=job_config
) # Make an API request.
load_job.result() # Waits for the job to complete.
destination_table = client.get_table(table_id)
assert destination_table.num_rows > 0
print("Loaded {} rows.".format(destination_table.num_rows))Input file looks like this,
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
{"name": "Arizona", "post_abbr": "AZ"}
{"name": "Arkansas", "post_abbr": "AR"}Loading from Local json file
Same input file as above but from local
# Load JSON from local to BQ
import io
from google.cloud import bigquery
# Construct a BigQuery client object.
client = bigquery.Client()
# TODO(developer): Set table_id to the ID of the table to create.
filename = 'us-states.json'
table_id = "<<project-name>>.test_public_data.us_states_jl"
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("name", "STRING"),
bigquery.SchemaField("post_abbr", "STRING"),
],
source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
)
with open(filename, "rb") as source_file:
job = client.load_table_from_file(source_file, table_id, job_config=job_config).result()
assert job.output_rows > 0
print("Loaded {} rows into {}".format(job.output_rows, table_id))Loading newline delimited JSON file from Pandas
In this example, dataframe is converted into JSON object and loaded
# Load JSON data from Pandas to BigQuery
import pandas as pd
import numpy as np
from google.cloud import bigquery
import os, json
### Converts schema dictionary to BigQuery's expected format for job_config.schema
def format_schema(schema):
formatted_schema = []
for row in schema:
formatted_schema.append(bigquery.SchemaField(row['name'], row['type'], row['mode']))
return formatted_schema
### Create dummy data to load
df = pd.DataFrame([[2, 'Jane', 'Doe']],
columns=['id', 'first_name', 'last_name'])
### Convert dataframe to JSON object
json_data = df.to_json(orient = 'records')
print(json_data)
json_object = json.loads(json_data)
### Define schema as on BigQuery table, i.e. the fields id, first_name and last_name
table_schema = {
'name': 'id',
'type': 'INTEGER',
'mode': 'REQUIRED'
}, {
'name': 'first_name',
'type': 'STRING',
'mode': 'NULLABLE'
}, {
'name': 'last_name',
'type': 'STRING',
'mode': 'NULLABLE'
}
project_id = '<<project-name>>'
dataset_id = 'test_public_data'
table_id = 'test_jsonload'
client = bigquery.Client(project = project_id)
dataset = client.dataset(dataset_id)
table = dataset.table(table_id)
job_config = bigquery.LoadJobConfig()
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON
job_config.schema = format_schema(table_schema)
print(job_config.schema)
# Default is append
job = client.load_table_from_json(json_object, table, job_config = job_config).result()
destination_table = client.get_table('{}.{}.{}'.format(project_id, dataset_id, table_id))
print("Loaded {} rows.".format(destination_table.num_rows))